
Linda Shapiro

Hannaneh Hajishirzi

Deepali Aneja

Sachin Mehta

Bindita Chaudhuri

Beibin Li

Meredith Wu
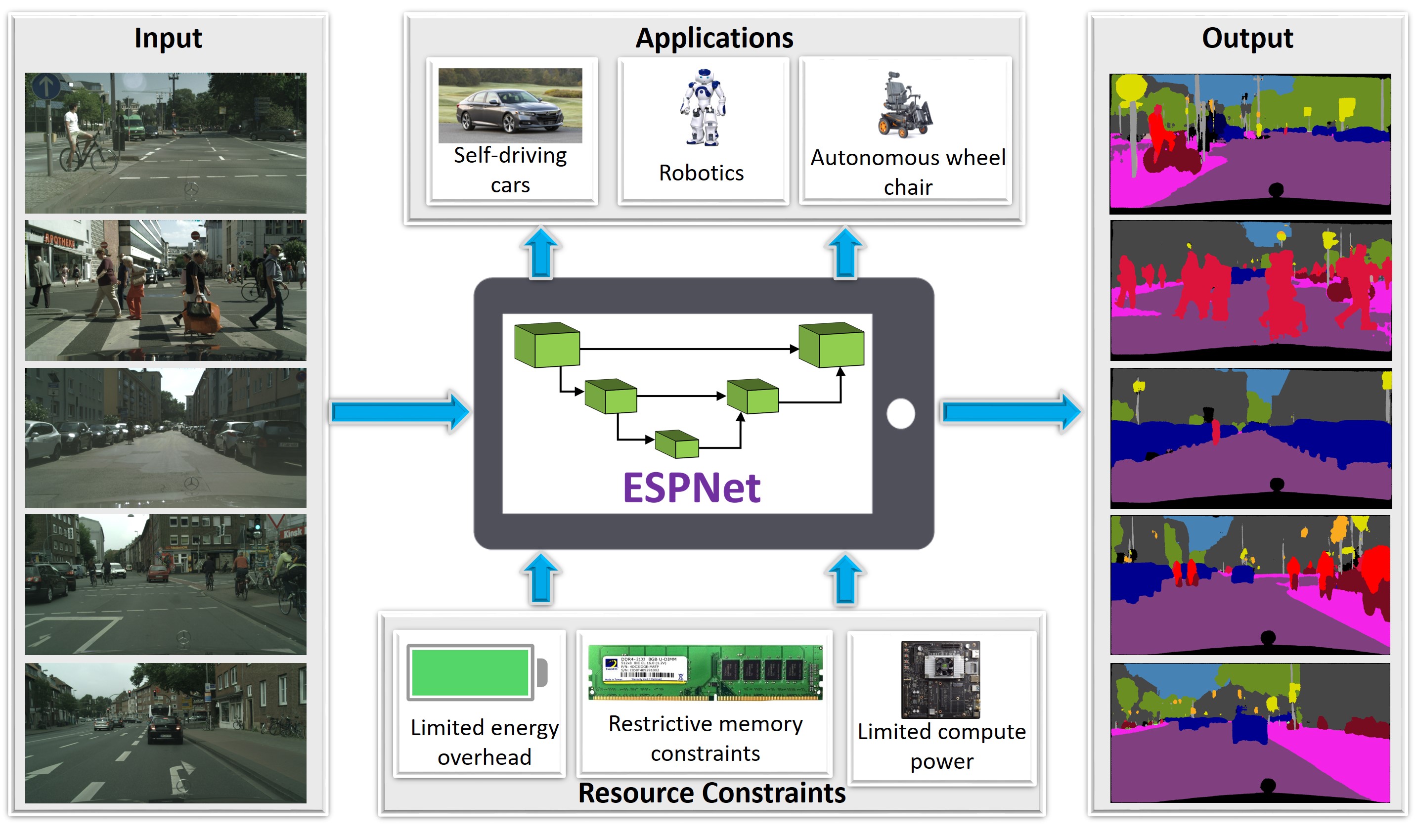
Deep Learning for Computer Vision
Deep Convolutional Neural Networks (DNNs) have achieved high performance in visual recognition tasks such as image classification, object detection, and semantic segmentation. At the University of Washington, we design new DNN-based architectures as well as systems for important real-world applications such as digital pathology, expression recognition, and assistive technologies.
|
Linda Shapiro |
Hannaneh Hajishirzi |
Deepali Aneja |
Sachin Mehta |
Bindita Chaudhuri |
Beibin Li |
Meredith Wu |
Project Page |
|
||

Project Page |
|
||
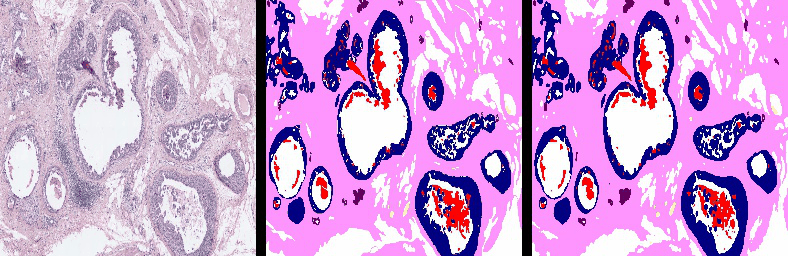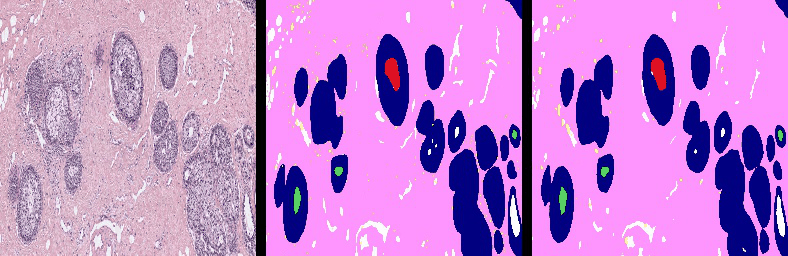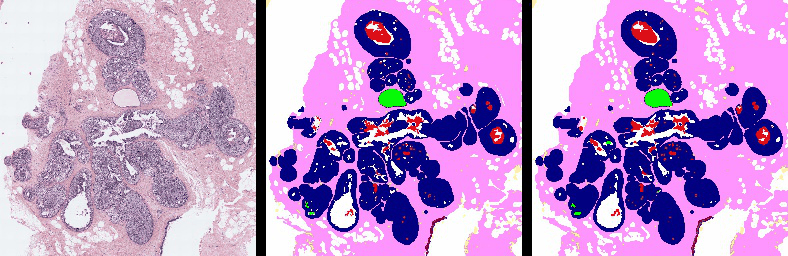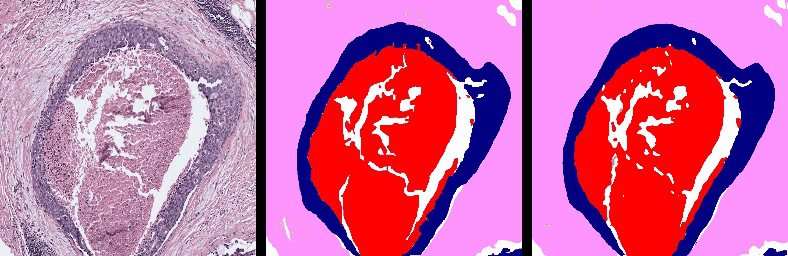
Project Page |
|